What Have PostgreSQL Functions Ever Done for Us?
Hey, DDD developers. What's stopping you from crafting beautiful, efficient domain models with these? With these obsolete, dusty old PostgreSQL functions and stored procedures?
What are we, stuck in the 90s or something?

Besides — what have user-defined functions and stored procedures ever really done for us?
Let me actually answer that. Not with hand-waving, but with a tiny bookstore I can fit on your screen.
Here's the schema. Three tables: books, orders, a little price history. Standard stuff.
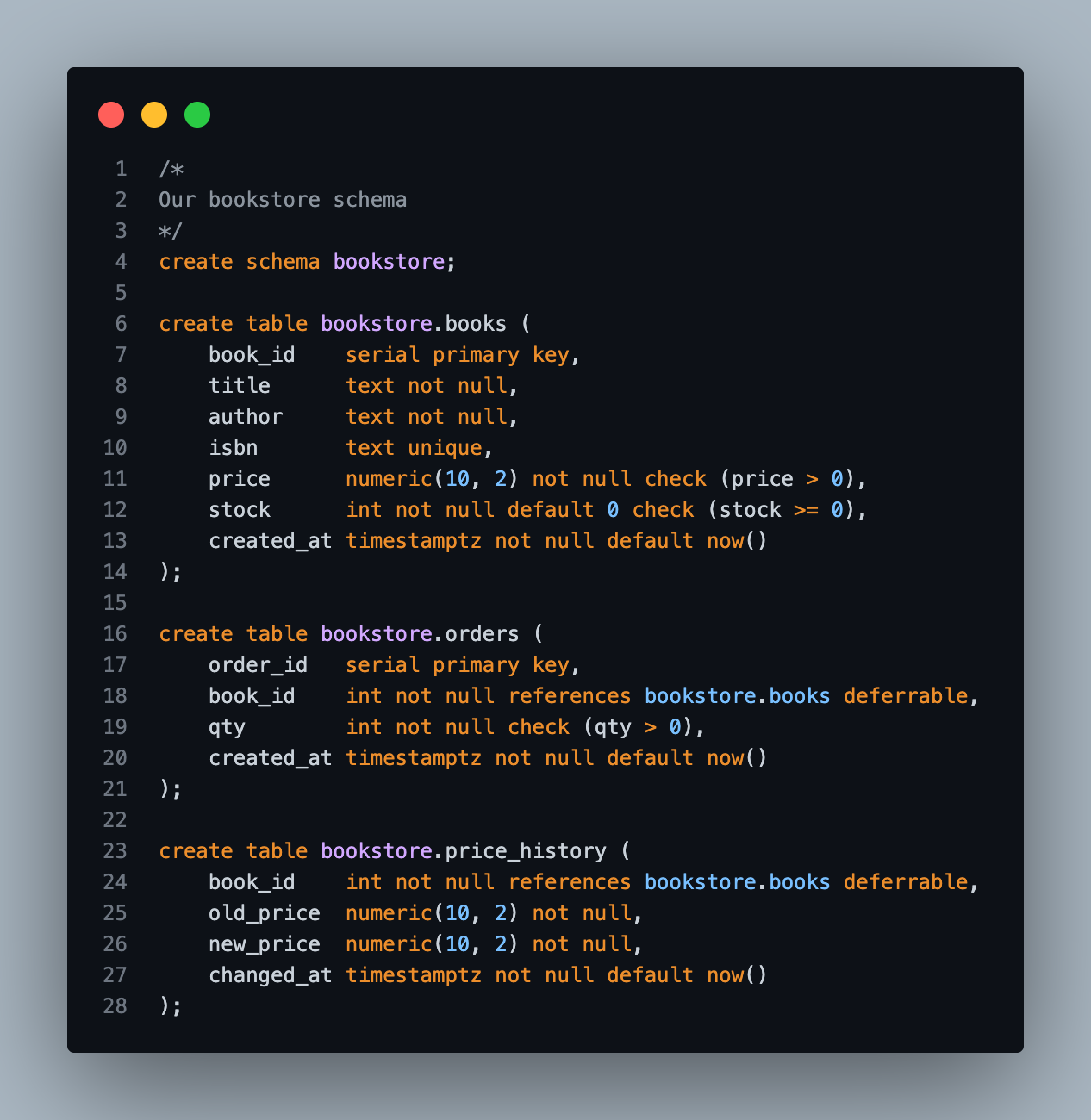
These tables? Private parts. Nobody outside the database touches them directly. Ever. Instead, every command and query the application is allowed to run lives in a function, in its own schema:
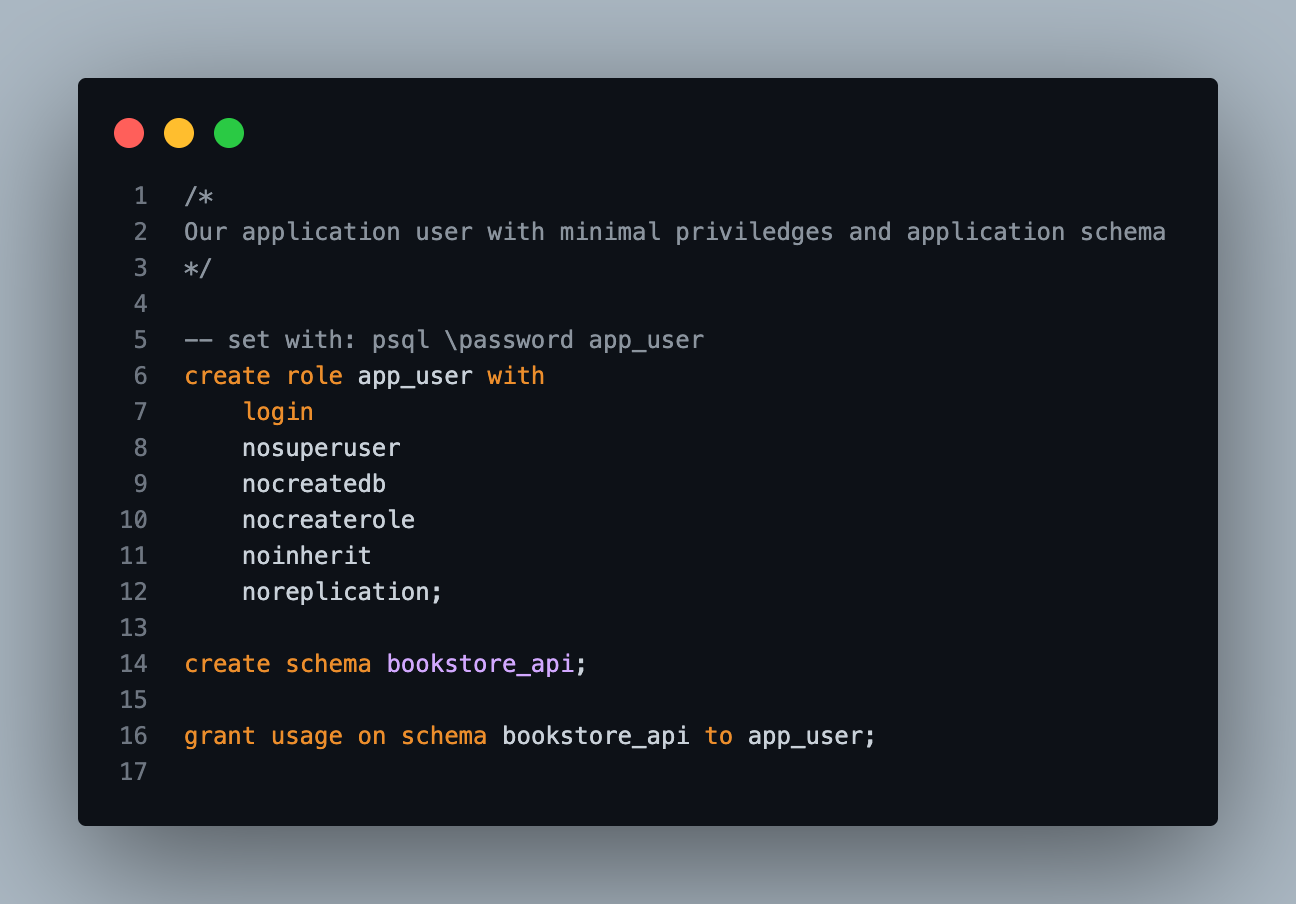
That app_user can login. That's pretty much it. nosuperuser, nocreatedb, nocreaterole, noinherit. It gets usage on the bookstore_api schema and nothing else. No tables. No data schema. Just the functions I decide to expose.
To borrow some OOP vocabulary: those functions are my data contracts. Parameters are the input contract, the result set is the output contract. The tables behind them can do whatever they want. The contract doesn't budge unless the application does too.
And if you strap NpgsqlRest on top, every one of those functions becomes a REST endpoint automatically — no controllers, no DTOs, no mappers. Your SQL is the API.
OK. But besides being a tidy mental model — what have they ever done for us?
Type Safety?
Here's the search API. One function, list_books:
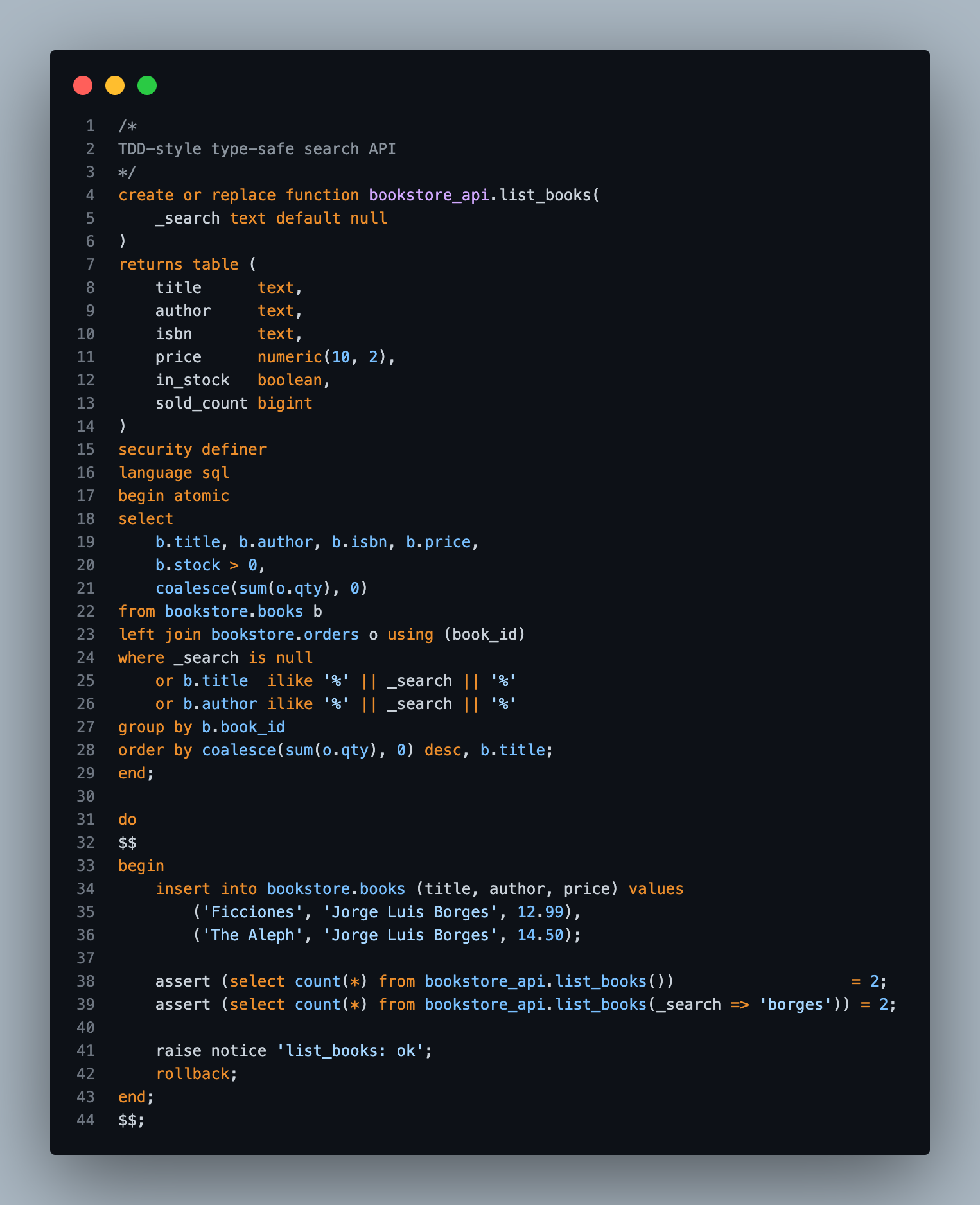
create or replace on every build re-validates the whole signature: every column name, every type, every table it touches. Rename a column in books, change price from numeric to int, drop something — and the build screams. No type or name change slips through unnoticed.
And as a bonus: strap NpgsqlRest on top and those same types propagate straight into your frontend as generated TypeScript. You're type-protected on every front, from the table to the React component.
OK — besides Type Safety — what have user-defined functions and stored procedures ever done for us?
Real Encapsulation?
The tables and types are invisible to the application. It can't see them. It can't SELECT * FROM bookstore.books. All it knows is list_books(_search).
Which means I can do whatever I want behind the curtain — split a table, denormalize it, archive half of it to cold storage, add a price_history audit on every update like in update_price here:
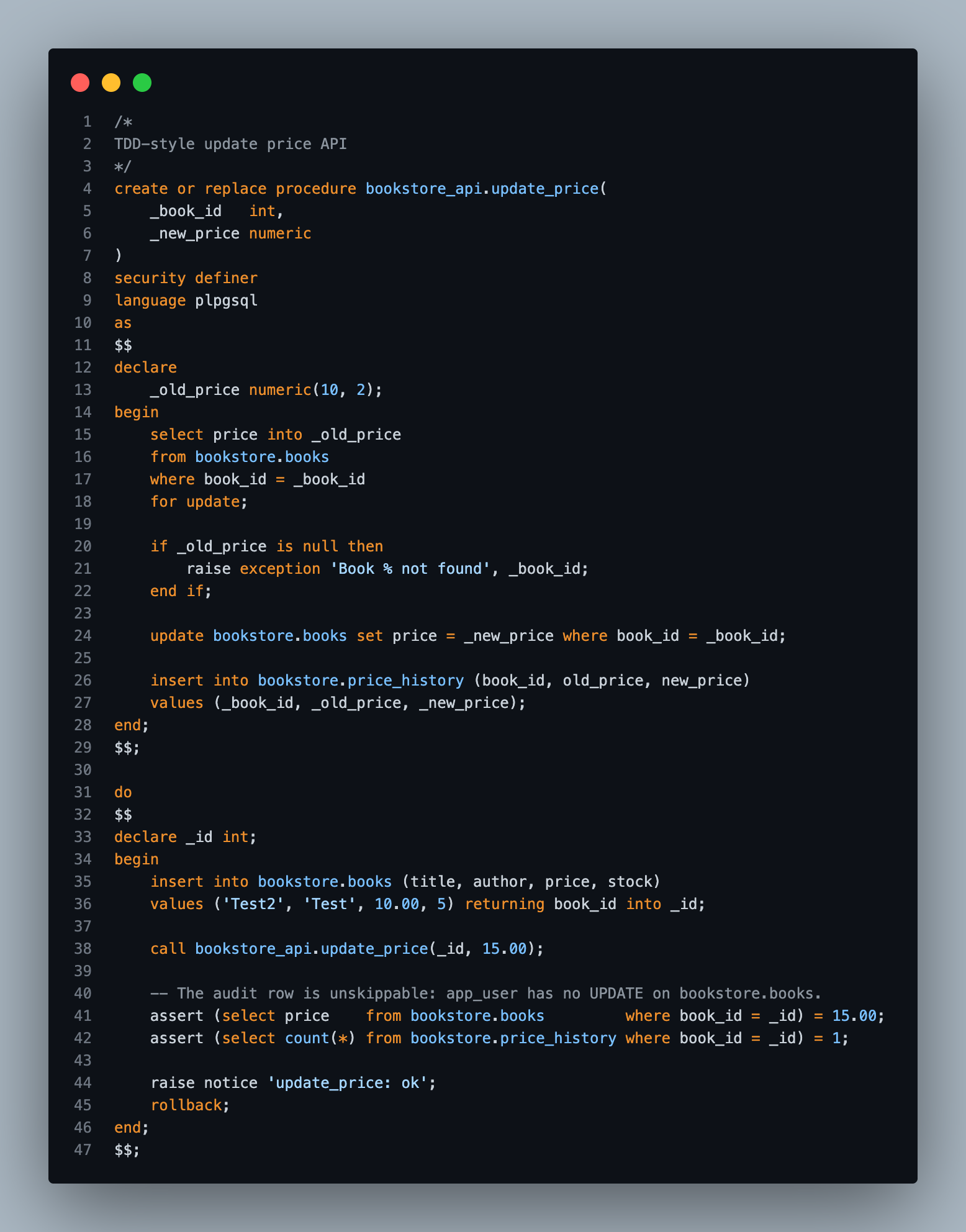
The application never finds out. The contract didn't move an inch.
OK — besides Type Safety and Real Encapsulation — what have user-defined functions and stored procedures ever done for us?
Zero Downtime?
Same deal. You split, denormalize, archive, rewrite the guts of a function — and not only does the API not move, you do it with zero downtime. create or replace function is atomic. No deploy. No container restart. No rolling anything. The next call just runs the new body.
OK — besides Type Safety, Real Encapsulation, and Zero Downtime — what have user-defined functions and stored procedures ever done for us?
Performance?
Look at place_order:
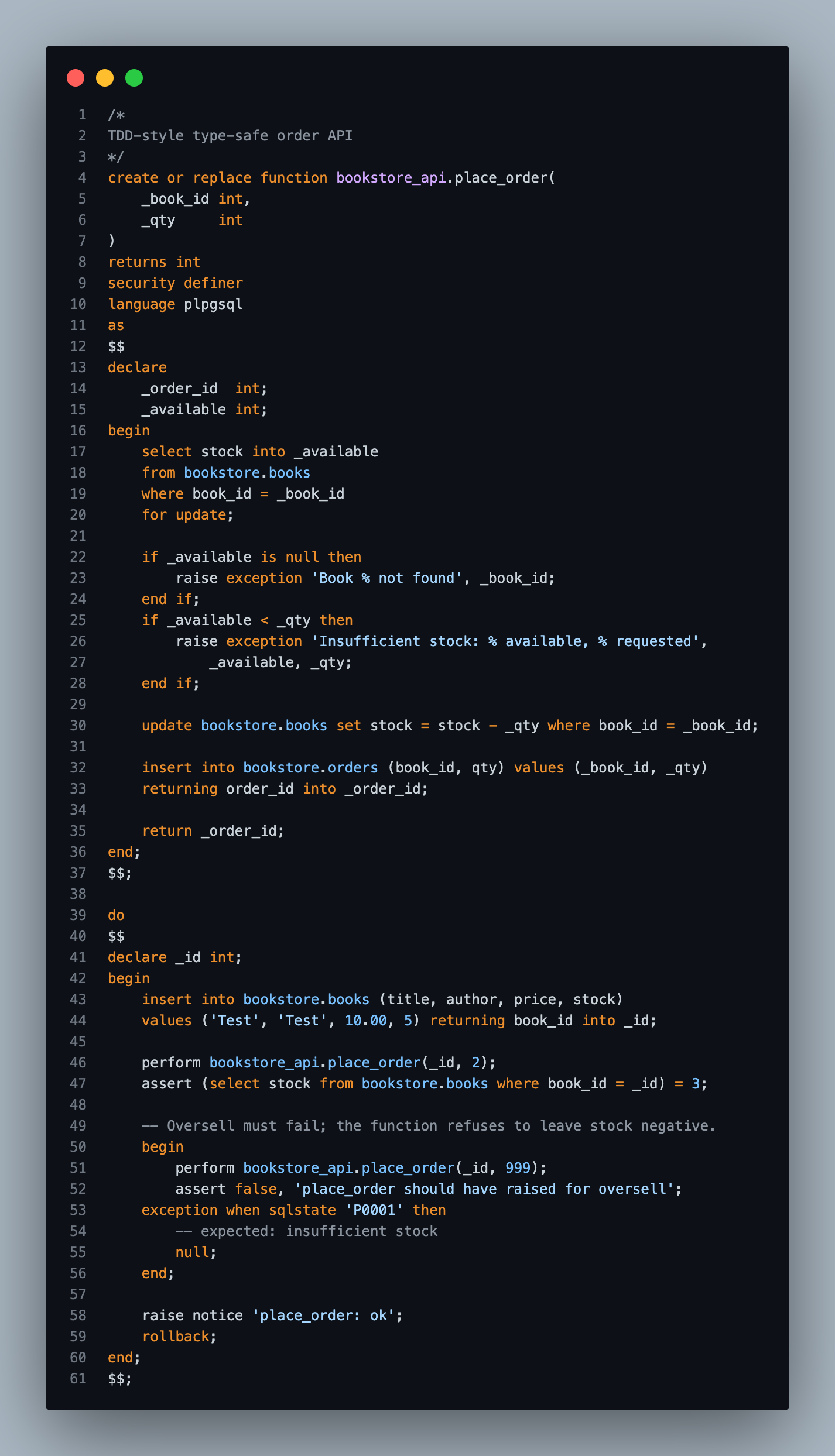
Check the stock, validate it, decrement it, insert the order — all of it in one single round trip to the database and back. From the application's point of view it's one call. The unnecessary network chatter — the read, then the read, then the write, then the other write — is reduced to zero.
OK — besides Type Safety, Real Encapsulation, Zero Downtime, and Performance — what have user-defined functions and stored procedures ever done for us?
Race Conditions Minimized?
Same place_order again. Fewer round trips means less time spent on the wire, which means latency drops, which means the window where two orders can fight over the last copy of Ficciones shrinks dramatically. Add the select ... for update and that window basically closes. Try doing that cleanly across four separate ORM calls.
OK — besides Type Safety, Real Encapsulation, Zero Downtime, Performance, and Race Conditions Minimized — what have user-defined functions and stored procedures ever done for us?
Security?

Your ORM is still connecting with a God connection — a role that can do anything and everything to every table. We don't. We use the principle of least privilege, the same way the army does. They call it "need-to-know." If you're captured, you can't give up what you were never told.
That's exactly what app_user is. It can call functions in one schema. It cannot read a table, cannot drop one, cannot escalate. So even if those credentials leak — out of the codebase, out of the infra, out of some forgotten .env in a public repo — the attacker gets to call the same endpoints your frontend already calls. They don't get to dump your data. The God connection credentials never went anywhere a thief could reach.
Alright, alright — besides Type Safety, Real Encapsulation, Zero Downtime, Performance, Race Conditions Minimized, and Security — what have user-defined functions and stored procedures ever done for us?
A Short Test Loop?
Look at the bottom of every one of those screenshots. See that do block?
sql
do
$$
begin
insert into bookstore.books (title, author, price) values
('Ficciones', 'Jorge Luis Borges', 12.99),
('The Aleph', 'Jorge Luis Borges', 14.50);
assert (select count(*) from bookstore_api.list_books()) = 2;
assert (select count(*) from bookstore_api.list_books(_search => 'borges')) = 2;
raise notice 'list_books: ok';
rollback;
end;
$$;Seed. Assert. Rollback. It lives at the end of the same SQL file as the function. I re-run the file in psql — the function gets create or replace'd, the test runs, I get list_books: ok, and the transaction rolls back so the database is exactly as it was.
Milliseconds. No build. No test runner. No mocked database. No spinning up half of Docker to find out my WHERE clause was wrong.
Oh God, oh man — besides Type Safety, Real Encapsulation, Zero Downtime, Performance, Race Conditions Minimized, Security, and a Short Test Loop — what have user-defined functions and stored procedures ever done for us?

...
Yeah. I really don't know either.
So, DDD developers
If you actually want to learn these ancient, obsolete, stuck-in-the-90s techniques — type-safe contracts, real encapsulation, least-privilege security, a test loop measured in milliseconds — I'll be running free workshops (and consulting) for NpgsqlRest users after this summer.
Drop a comment if you're interested.
And if you'd rather just start: your SQL is already the API, you just haven't pointed NpgsqlRest at it yet.
More Blog Posts:
The Backend That Writes Itself (Slide Deck) · Case Study: 74 Endpoints, Zero Backend Code · TypeScript Code Generation Walkthrough · NpgsqlRest 3.13.0: Production Patterns · SQL REST API · Excel Exports Done Right · Passkey SQL Auth · Custom Types & Multiset · Performance & High Availability · Benchmark 2026 · End-to-End Type Checking · Database-Level Security · Multiple Auth Schemes & RBAC · PostgreSQL BI Server · Secure Image Uploads · CSV & Excel Ingestion · Real-Time Chat with SSE · External API Calls · Reverse Proxy & AI Service · NpgsqlRest vs PostgREST vs Supabase · Optimization Labels 101
Get Started:
Quick Start Guide · Benchmark Results · Security Guide · Function Annotations